In the last two decades we have seen the emergence of new computing models, a new discipline called DevOps and a new way of packaging and deploying applications using containers. However, this new way of provisioning infrastructure and deploying applications has brought a new set of challenges that are putting a lot of burden on enterprise IT. Primarily, there is a proliferation of tools that IT needs to manage, operate and stitch together to handle these fast paced application development environments. This needs a new approach to handle the next generation of applications and Hyper-converged DevOps is an approach that solves these problems in an elegant manner.
Rise of Cloud Computing and DevOps
The first decade of the 21st century was dominated by virtualizing infrastructure and converging compute, storage and networking stacks into a shared pool of resources managed by VMware vSphere, Microsoft SystemCenter, Red Hat Virtualization. Previous server, storage and network admins became virtualization admins and could be a lot more productive by managing 10x the volume of servers as before. The last decade (2010 onwards) saw the rise of cloud computing and Infrastructure-as-a-service (IAAS) where AWS consolidated four core computing functions (Storage, Compute, network and security) and offered them as a service with little operational overhead. Given the simplicity of original IAAS services, IT operations were easier. This also led to the rise of Infrastructure as Code and a new discipline in enterprises called “DevOps”
The IAAS consumption model, API driven provisioning and management of infrastructure created a new discipline called “DevOps”.
Rise of Containers, Micro-services and Cloud Native Services
In addition to cloud computing, docker and containers have ushered an era of Micro-services. An application now consists of multiple containers each running a separate micro-service. These services can be deployed, scaled and upgraded independent of each other. To support all this, even on the infrastructure front, what used to be largely a monolithic set of components are now fragmented into many small components or services. Each micro-service has its own set of load balancers, API gateways, DNS names, security groups, IAM policies and data stores.
In addition to splitting an application into micro-services, there is also increasing adoption of cloud native services as part of application stack. For example, in public clouds, there has been an explosion in the number of application centric platform services like Object store, databases, message queues, notification systems, NoSQL databases, key-value stores and so forth. Figure 1 shows the comparison of how AWS has evolved in the last 10 years.

An application today is a combination of micro-services, infrastructure services and cloud native services. There is an explosion in the use of many cloud native services to get faster deployment and upgrades.
Taxonomy of DevOps Automation Stack
With the original IAAS model, the underlying infrastructure constructs (like VM, storage, network, load balancer and DNS) would rarely change and the updates were limited to the application code. Today, deploying and operating a cloud native application involves multiple devops functions at various layers of infrastructure.
In fact, cloud has blurred the boundary between what is application and what is infrastructure. For example, with Kubernetes, infrastructure constructs like ports, load balancers, DNS names are now part of the application deployment specification.
Figure 2 shows the modern day devops automation stack. It consists of five different layers each performing a specific function in terms of application deployment, reliability and security.
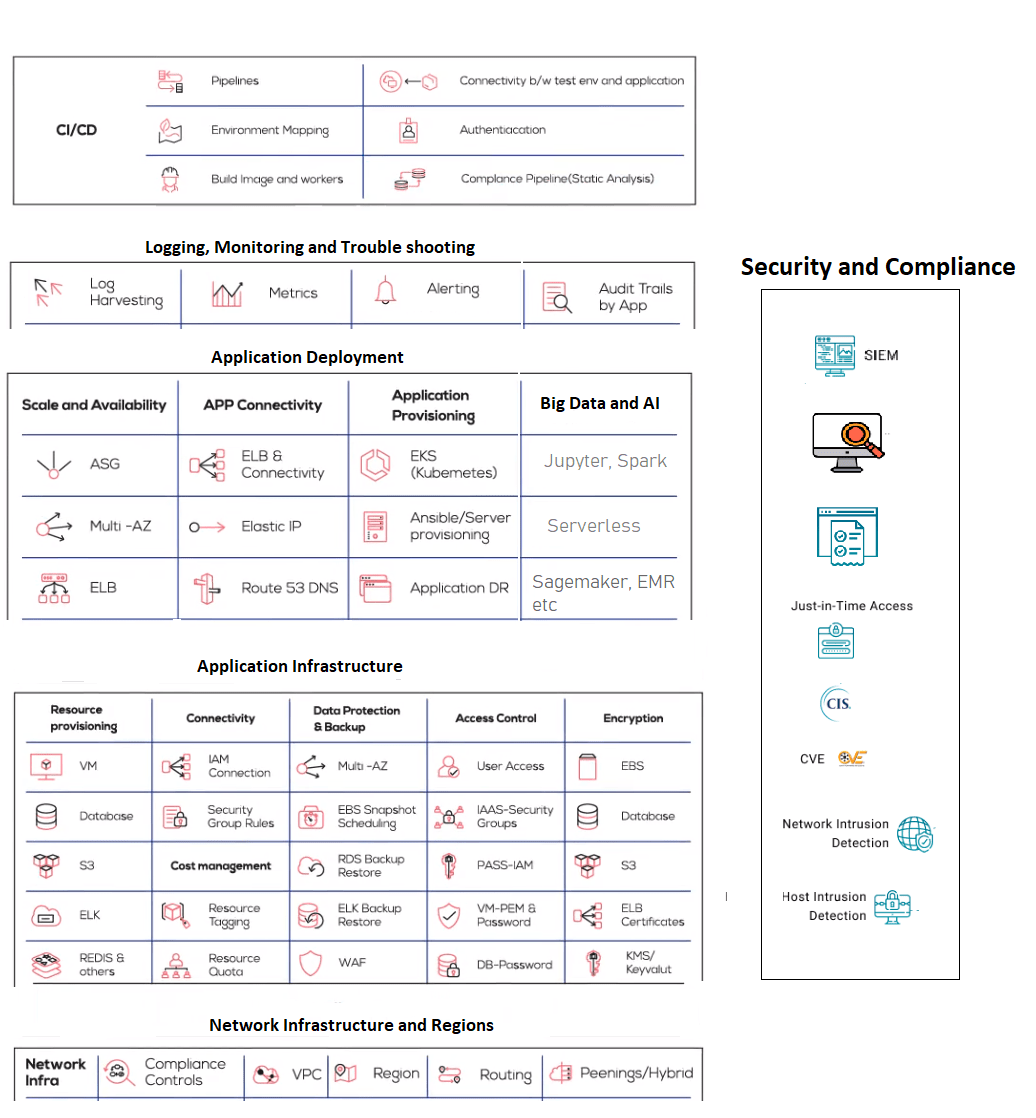
1. Networking, Regions and Availability Zone.
This is the base layer of the stack where we create the virtual networks, subnets, NAT gateways, hybrid connectivity and availability zones. Relative to the rest of the stack this layer is not changed frequently. But, it is critical to set it up properly as any changes later can be quite disruptive. One has to follow the guidelines of a well-architected framework and some basic security controls. Hybrid connectivity across multiple such layers in different locations can be complex but that is largely a one-time operation.
2. Application Infrastructure (Provisioning and Configuration)
Public cloud has added the most feature-set in this layer. This includes provisioning resources like Virtual Machines, Databases, Elasticsearch, Redis, object stores, message queuing services like SQS, Hadoop clusters and their access policies, security groups and encryption. Backups, disaster recovery, password management, single sign-on, and just-in-time access would fall in this category as well.
While this layer provides the most powerful functionality from an application perspective, it is also the most complex in terms of the DevOps workflow due to the number of moving pieces and their respective configuration techniques.
3. Application Provisioning
In this layer of the stack, we have container deployments (Kuberenetes), serverless deployments and ETL pipeline automation that includes Spark, Hadoop and Jupyter. These deployments include updates to load balancers, auto-scaling groups, DNS, health checks, rolling upgrades and blue-green deploys.
4. Logging, Monitoring and Incident management
Engineering teams spend a significant part of their time debugging. While there are tools like ELK, Sumo Logic, SignalFx, CloudWatch, Sentry that implement these functions, they are still required to be orchestrated and configured in the context of the application. For example, when we are looking for metrics related to say an airline ticketing application, we should not have to look through the LB metrics for cargo processing service.
To collect logs we need to drop log collectors in the right servers. Based on the application, we need the log collector to have right tags so that there is clear separation and indexing in the central logging dashboard. Similarly, for metrics one needs to collect them from application components like web servers and corresponding infrastructure pieces like the relevant databases, load-balancers and virtual machines. These metrics might come from different sources like Cloud Watch for infrastructure and a New Relic setup for application.
5. CI/CD
In order to do continuous build, test and deployment, companies are moving towards CI/CD systems. The common tasks here are setting up a framework for developers and QA to build and execute their test pipeline. One needs build frameworks on top of systems (like Jenkins, CircleCI, CloudBees, and others) with the application runtime dependencies like the right version of programming language (Java, python etc). The servers or containers where the tests will run need to have the appropriate access to the environment where the application is hosted like the databases, load balancers, kubernetes cluster and API gateways. Multiple environments like dev, staging and production should be set up in a consistent manner with their own settings and access controls. Many steps in the release pipeline may involve security functions like penetration testing and vulnerability assessment.
6. Security and Compliance
This is a discipline by itself, separate from DevOps, called SecOps. This touches all aspects of the stack we have discussed above. In regulated industries, many of the functions described above have to be implemented with a certain specification provided by a compliance standard. For example, one could achieve segregation of components via security groups over a common virtual network, but PCI DSS v1.2 mandates that the production and non-production address spaces be different.
Adding security and compliance controls on top of existing infrastructure can be a very exhaustive process especially if the infrastructure was not originally built with compliance guidelines in mind.
Figure 3 shows the snapshot of the list of controls needed for PCI DSS v1.2 taken from the AWS implementation guide There are a total of 79 infrastructure level controls.
Overall these Security controls can be categorized into two areas:
A. Provisioning Time Security: These controls need to be put in place during the provisioning of the resources and will likely require downtime if they were to be changed later. Examples include virtual networks, security groups and disk encryption. In a typical compliance standard this constitutes about 60% of the overall controls.
B. Post Provisioning controls: These are put in place in a running system and many of these are monitoring controls. For example, vulnerability assessment, file integrity monitoring, virus scanning, intrusion detection and incident management.

When developing infrastructure automation, there can be a very wide spectrum of automation levels. How do you know which is right for you? Our free white paper can help. Read it now:

Current State in DevOps Automation
Today engineering teams convey their application deployment needs as a high level specification to the DevOps engineers who then stitch together the full taxonomy of functions using a set of DevOps tools. Based on the application architecture and design, DevOps engineers would author automation scripts and workflows using tools of their choice. This process is shown in Figure 4.
One can already imagine the effort required to build a fully automated DevOps infrastructure. If the environment has to be compliant to standards like PCI, HIPAA and HiTrust then that adds further complexity. For example, say we have to estimate what would it take to implement a fully automated and PCI compliant infrastructure of an application that spans 50 virtual machines.
By putting an estimate in man hours for each DevOps function and each of the 75 PCI controls we can conclude that it would take on average 6 months for one DevOps and one secops engineer working in tandem to create a fully automated and PCI compliant infrastructure.
Infrastructure as Code is the most popular approach toward building cloud automation. There are different such coding tools each tailored for the stitching process of different DevOps functions. For example, Terraform is popular for network and application infrastructure as defined in Figure 2, Ansible is used for OS level provisioning and Helm charts for Kubernetes. As the infrastructure grows, the bigger the code base becomes. The harder it is to make changes as every change needs to be programmed, code reviewed, tested and then executed. As such, DevOps is one of the most difficult disciplines to hire because we are looking for two very different skills, programming and operations, in a single individual. So what can we do better to make it easier to automate DevOps tasks for today’s applications?
A New Approach: Hyper-converged DevOps Platform
Today, cloud is a de facto consumption model either on-premises or as a public cloud. But not long ago, on-premise IT functions had a very similar operations taxonomy. Getting basic application deployments used to take weeks, till AWS and Azure put an IaaS abstraction on top and removed all the operational complexities of server and compute virtualization, VSAN, VLANs, routing, network isolation, Operating system installation, load-balancers, databases. The DuploCloud team who were early engineers at Azure, were at the forefront of the IAAS / Public cloud disruption back in 2008. We believe a similar disruption is now due in the space of DevSecOps.
At DuploCloud, we have built a hyper-converged DevSecOps platform that automates all six layers of DevOps taxonomy that we discussed earlier.
The platform runs in a VM as part of a customer’s cloud account and is accessed by the users using a web UI, API and CLI interface. It receives application requirements as high level specifications and creates underlying infrastructure automatically while meeting all guidelines of the well architected framework and desired compliance standard. The platform implements all the functions outlined in Figure 2 and handles all compliance controls out-of-box. Infrastructure as Code is auto-generated. Figure 5 shows the new DevOps workflow using DuploCloud.
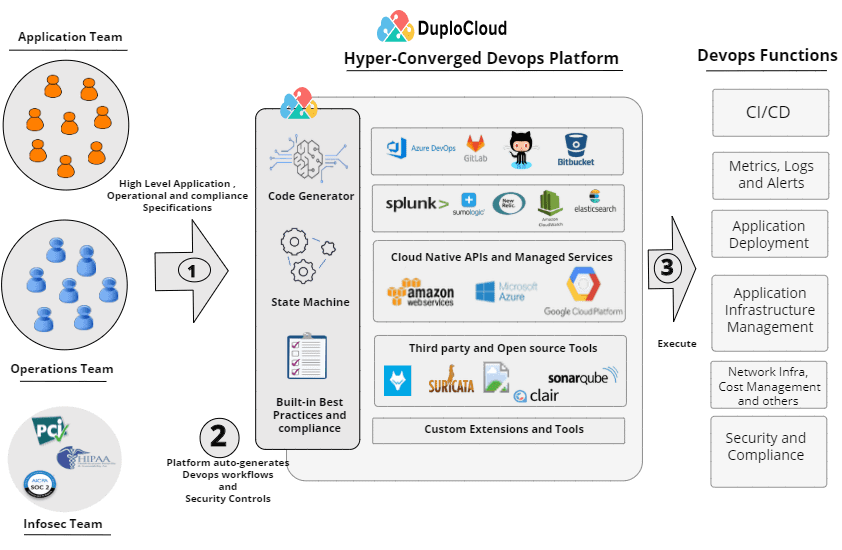
The platform relies on cloud native APIs and services for most DevOps and secops functions. For instance, for Kubernetes in AWS it would use EKS, for disk encryption it would orchestrate KMS keys. Many functions like intrusion detection, SIEM, APM (Application Performance Monitoring) where the cloud services fall short, DuploCloud uses industry standard open source and third party tools. For example, for SIEM it uses OSSEC (Wazuh), for network intrusion detection it uses Suricata and for Linux virus scanning it uses ClamAV. The platform is extensible to alternate tools.
If you think that you are spending too much time and effort in dealing with your DevOps stack and meeting compliance controls, please check out duplocloud.com for more details or contact us at info@duplocloud.net.


