
It happens to the best of us. You’ve got one or two engineers… and they know everything. They totally get why that weird Terraform module exists. They’re clear on which Slack channel has the runbook for 3 am alerts.
Oh, and they know the actual deployment process… not that outdated wiki version.
These guys are your single points of failure. And statistically, at least one will leave you high and dry this year.
When they do, all those months of tribal knowledge, stuck in their head, walk right out the door. It will take you six months to get your next hire up to the same baseline, at least.
Meanwhile, your team just flails about.
Most companies think of this whole scenario as a people problem, but it’s not.
It’s a systems problem.
And while you can’t “fix” people, you can absolutely fix systems.
Here’s how:
Tribal Knowledge Is The Serial Killer
The cycle repeats over and over, serially, at most companies.
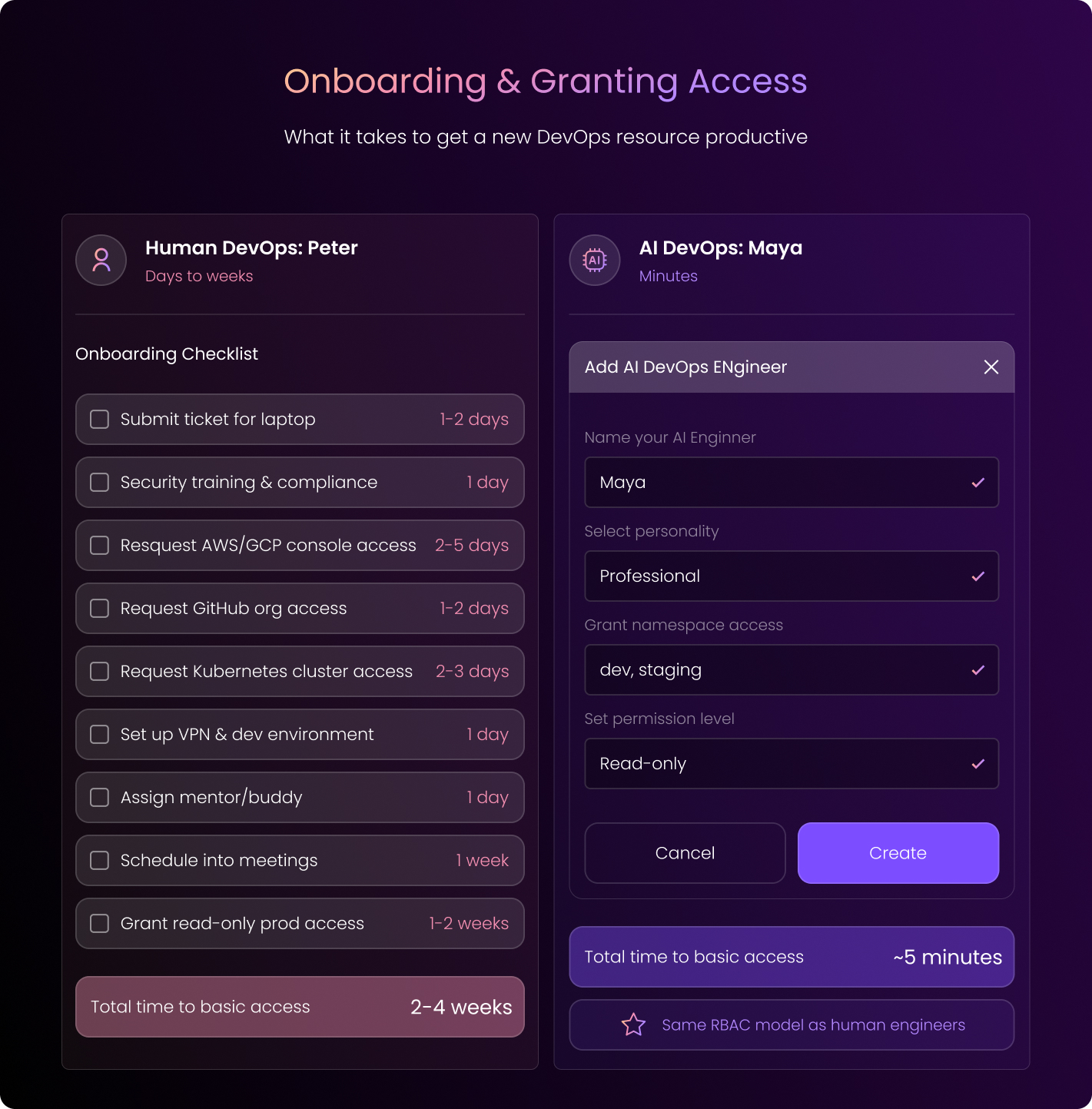
Allow us to introduce you to your imaginary DevOps engineer, Peter.
Peter joins your company and spends months learning your systems. He pores over sparse docs, he chats up his busy colleagues, and he reverse-engineers your IaC.
No wonder Peter becomes indispensable. He’s the only one who knows how to debug that flaky pipeline. He’s the go-to guy who understands your Kubernetes networking. And, yeah, he’s the guy with the necessary context to fix interrupted production, fast.
Everyone’s happy… until your competitor offers Peter 20% more than you’re paying him, and he accepts.
He leaves.
And all that knowledge disappears.
Not such a big deal, right?
You hire Sarah, and she’s great. She spends months learning your systems.
And guess what: the cycle repeats.
Meanwhile, every incident takes a long time, more time than you have. Why?
Because the same problems have to be solved from scratch over and over.
This sounds familiar, doesn’t it?
Keep Your Knowledge In-House
Look, people will always leave, and you can’t change that. There’s always going to be a better offer.
The real problem is that knowledge lives in their heads.
It should live in your systems.
And it can.
What if every debugging session got automatically documented? What if every incident resolution got stored and indexed? What if the next similar issue were resolved in minutes because the system already knew the answer?
That system is exactly what we’ve built at DuploCloud.
Meet Maya: Your Engineer Who Will Never Leave
Maya is the DuploCloud AI DevOps Engineer. You’ll onboard her just like you would a new hire, but she works a little differently.
First, she learns your systems in hours, so you save months. Maya runs discovery across everything she can access:
- Kubectl commands
- Terraform plans
- API calls
- Your internal docs
Within hours, she’s giving you topology reports and documentation that can now live in your repos.
Say goodbye to tribal knowledge.
Second, she automatically documents absolutely everything. When Maya investigates an incident, the entire session gets captured. You’ll be able to track commands, logs, and the root cause. You’ll also see what Maya proposes as a fix.
That way, the next time a similar issue occurs, Maya can resolve it even faster because she already has context.
Finally, she never forgets, and she never leaves. With human engineers, you have to deal with context-switching. They take vacations. And, yes, they quit.
But Maya retains everything. So your infrastructure knowledge grows instead of flowing out the door over and over.
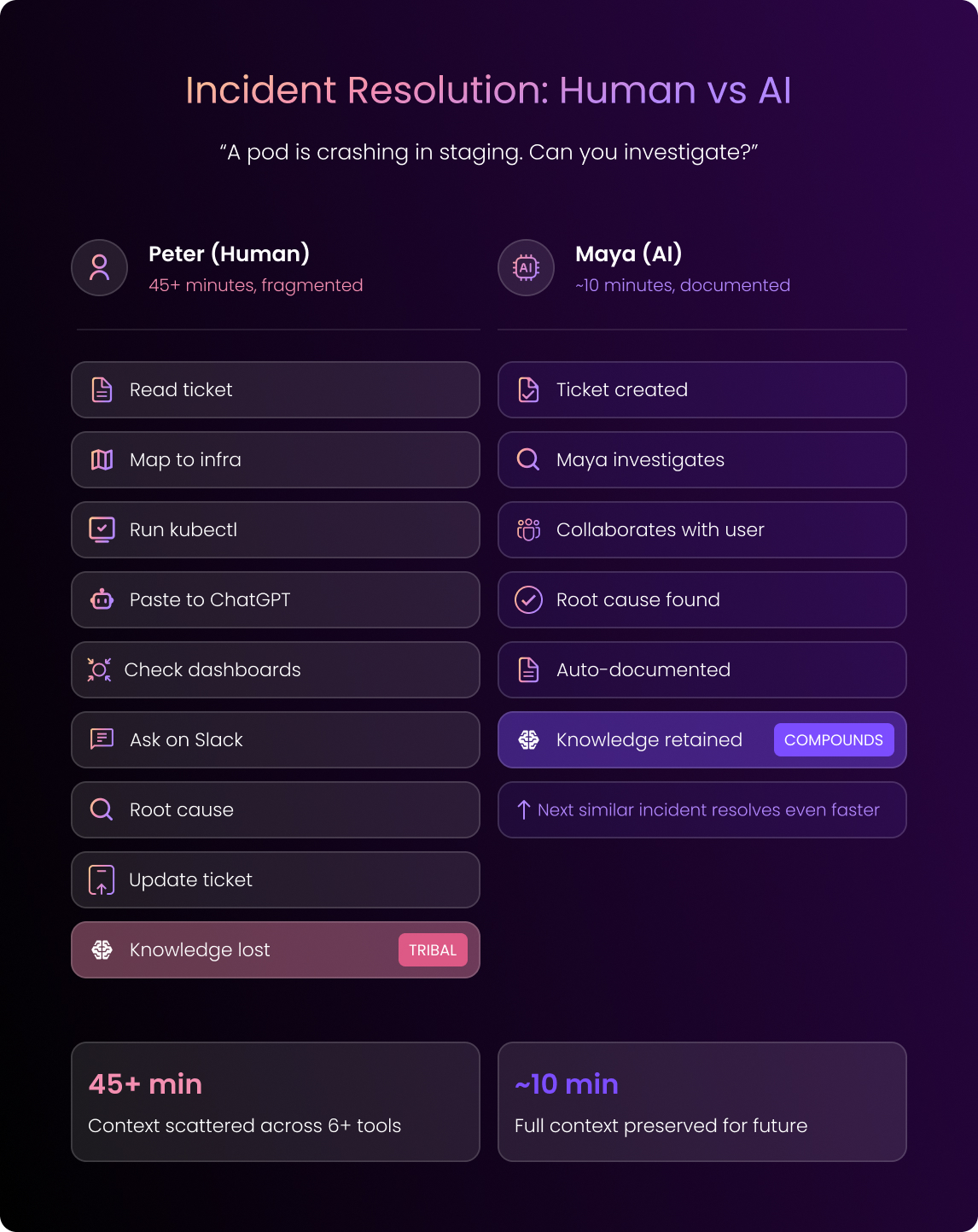
Same Incident, Different Outcomes
Let’s look at a specific scenario to see how this plays out:
A pod keeps crashing in staging.
With your human engineer, Peter, he:
- Reads ticket and maps service to cluster
- Runs kubectl and pastes the output to ChatGPT
- Checks your Grafana dashboards
- Asks around on Slack
- Finds the root cause
- Updates the ticket with minimal context
In the end, the issue gets resolved, but all that knowledge stays in Peter’s head
And the total time it took was about 45 minutes, but all that context is lost.
In contrast, with the AI agent, Maya:
- The user opens a ticket
- Maya investigates the issue in real time
- Collaborates with the user and identifies the root cause
- The full session syncs to the ticketing system
Now, all the knowledge will be stored for future incidents.
The total time it took was about 10 minutes, and the context is preserved forever.
The Effect, Compounded
Now, here’s what the switch to Maya looks like over time:
Month 1: Maya resolves incidents at mid-level engineer speed. But she documents everything.
Month 3: Maya is now able to use the context from previous issues to resolve new issues faster than before.
Month 6: Six months in Maya can handle 60% of common Kubernetes issues without human intervention. Meanwhile, your team can focus on architecture instead of constantly putting out fires.
Month 12: Your infrastructure knowledge base is deeper than any single engineer could hope to maintain. Your new hires onboard faster because you’ve got thorough documentation stored, thanks to Maya.
Oh, and no one can poach her away from you.
But, But, What About Production?
You already know that you should never let any engineer, human or AI, run wild in production.
To that end, Maya works within the following guardrails:
Permission inheritance. Maya will use your existing RBAC. If your engineers can’t delete production pods, neither can Maya.
Human-in-the-loop. Maya can only propose changes, and then she has to wait for approval on anything consequential. She merely investigates and prepares. It’s always the humans who decide.
Full audit trails. Every action gets logged, complete with attribution for every step of the way.
Environment isolation. Maya in staging can’t touch production. You’ll always get architectural enforcement. It’s not just policy.
The Math
Now, how much money will you save?
For a Senior DevOps engineer: You’ll pay $180-250k/year fully loaded
Time to productivity: They’ll be ready in about 3-6 months
Risk of departure: ~20% annually
Knowledge retained when they leave: Maybe 10%
But for an AI engineer:
- Maya onboards in minutes
- She’s productive in hours
- She never leaves
- She retains 100% of your knowledge
- She compounds her learning over time

The teams we’ve worked with who have run Maya report 60% of their common K8s issues auto-resolved. They also find they get 10-15 labor hours back. Plus, their documentation actually stays current.
So… Your Best Engineer Is Gonna Quit
You can’t stop it, but you can stop it from mattering.
You can keep relying on tribal knowledge and hope your key people stick around.
Or, you can build systems where knowledge compounds instead of walking out your door.
At DuploCloud, we’ve built a sandbox that lets you try Maya yourself.
There, you can create tickets, watch her investigate, and test the guardrails.
And you don’t even have to take a sales call.
Just bring your hands-on experience.
👉 Try the Duplo sandbox to explore how application-aware AI DevOps Engineers work in practice.
Your infrastructure knowledge should grow over time, not walk out the door every time someone leaves.


