
Platform Engineering was supposed to be the discipline that finally made cloud infrastructure self-service for Developers as against them waiting behind DevOps engineers. The Platform engineering team’s charter was to build an Internal Developer Platform (IDP) — a rich, self-service layer that abstracts away infrastructure so developers can ship without becoming Kubernetes and Terraform experts.
That was the mandate. In reality, while many DevOps teams renamed themselves Platform Engineers we still kept shipping the same things we always had — the same Terraform modules, the same CI/CD pipelines. Any small deviation on developer needs meant DevOps engineers had to get involved and the tasks would be queued for days. The rich IDP rarely showed up. The thing they were supposed to build turned out to be far harder than the thing they knew how to build.
The Problem — An IDP is a distributed system, not a catalog of scripts
Here’s the heart of it. The common mental model for an IDP was a catalog of pre-baked scripts behind a self-service UI — a developer clicks “create service,” and a Terraform module runs behind the scenes. Backstage gave this pattern a UI. But the overall architecture is rigid by design: every workflow has to be anticipated and hardcoded in advance, and the moment a developer needs something slightly different, the platform team has to go change the scripts. The UX seems like an automation Platform but everything behind it is brittle, and the team is right back to being a ticket queue.
A real IDP is something else entirely — a genuine distributed system with shared state and centralized context, access control across environments, audit trails, deterministic execution with SLAs, fault handling and retries, secrets management, and coordination across many engineers and many systems. Kubernetes, AWS these are examples of similar systems albeit operating at a different layer. AWS is Infrastructure-as-a-service, Kubernetes is Containers-as-a-service and the IDP is supposed to be DevOps-as-a-Service.
Why Platform Teams Couldn’t Build It
Building an as-a-service platform is a hard systems engineering problem, and platform teams — for all the rebranding — usually aren’t set up for it. The reason is structural, and it’s clearest when you compare how a software product reaches production versus how DevOps team’s automation does.
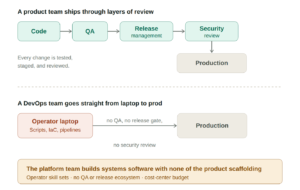
A product team ships code through layers of review, each one a function staffed to protect the product. A DevOps team goes straight from a laptop to production. So three things compound:
Operators, are not distributed-systems engineers.
Most platform engineers come from an operations background — great at running infrastructure, not typically trained to build a multi-tenant service with isolation, RBAC, retries, and audit guarantees. Renaming the team didn’t change its skill set.
No product ecosystem.
A real product has QA, release management, PMs, and designers dedicated to the product itself. A platform team has none of that. Whatever they build is unsupported software maintained by the same people operating production.
Cost-center budget.
An IDP generates no customer revenue. To management it’s a productivity tool, so its budget is thin. You can’t staff a multi-year systems-software effort that way.
Falling back to “more IaC under a new name” wasn’t a failure of effort. It was the most that could realistically be built under those constraints.
AI in DevOps has its own problems
AI dramatically lowered the bar for writing software. With Claude Code, an operator can write a Skill that subsumes complex automation scripts that otherwise had to be manually written. In that sense the turn around time for developer tickets from DevOps was faster but still infrastructure tasks were not self-serve. To achieve self-service DevOps engineers are attempting to build agents developers would interact with.
But there are 3 structural problems with this approach:
1 Claude Code to Enterprise Ready multi-player agents is extremely hard.
Claude Code is, by design, single-player: one person, one machine. That’s perfect for writing a feature. It isn’t what DevOps is. Operations is multi-player — that needs the following list of features that every agent needs to implement.
- RBACs and workspaces Shared
- AI sessions or Multi-player AI
- Skill distribution mechanism
- Context management across sessions, teams and projects
- Token cost management across users, workspaces, teams and projects
- AI Safety: Human-in-the-loop and determinism
- Slack and Teams integration
- Alerts and notifications
- and other such constructs that are table stakes in a Saas world.
2 Need for workflows.
Native AI’s UX is natural language but an IDP would need workflows, form, drop downs, views, dashboards and so on. Many of the workflows need to skip AI and go direct to scripts, so we need a router that can handle these seamlessly.
3 Many DevOps use cases are repetitive across organizations.
Such as ephemeral environments, kubernetes deployments, security scans, triaging infrastructure, security best practices, compliance controls and so on. These should be just bought, not built in house.
The end result is that in most organizations AI has made minimal impact on DevOps beyond DevOps engineers resolving their ticket queue faster by using coding agents.
The Fix — How DuploCloud changes the equation
DuploCloud inverts the build order. Instead of starting from scripts or bespoke agents and hoping the platform materializes, you start with a ready made but highly extensible platform and write only what’s specific to your organization. It’s a three-layer stack, solving each one of the 3 problems described above and the key point is how much of it is already built.
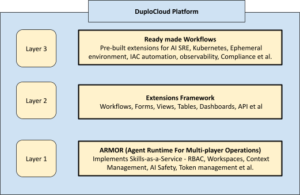
1 Layer 1 — ARMOR (Agent Runtime for Multiplayer Operations)
This is the foundation built on a “Skills-as-a-Service” principle.
- Platform engineering teams would write a skill and test it locally in their claude code then publish it to the platform.
- The platform has a set of MCP servers for external connections to systems like AWS, Azure, Kubernetes etc.
- MCP servers and skills are made available to each workspace.
- End users login to their team workspaces and start an AI session choosing from a desired set of MCP servers and skills.
- Behind the scenes for each AI session the system launches a claude session which gets the job done.
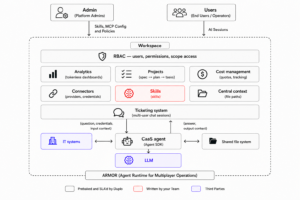
This whole thing is wrapped further into typical SaaS constructs like audit trails, usage metrics, rich RBAC, token quotas, context management capabilities, alerting and notifications and so on. Notice that the administrator has the choice to launch other agent SDKs like openAI, gemini or Open code instead of Claude. Thus delivering LLM independence.
This was an over simplified description. See this page for a detailed description.
2 Layer 2 — The Extension Framework
Where it becomes your IDP. You define a policy model — a taxonomy of the resources your platform manages. Each resource is mapped to a Skill that determines how the resource is provisioned and posts the results back to the platform for the users to view. Extension framework makes the platform fully customizable. One can build a simple workflow to launch a VM or a complex multi-resource environment as a service.
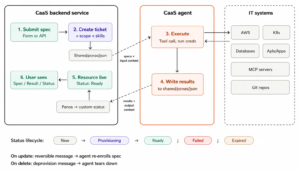
Extension Studio — Part of the extension framework is the extension studio which allows you to build and test an extension from a laptop just like you write code using claude. In this mode the entire platform runs in your laptop. It comprises a Claude skill for building an extension, an example extension code and a Docker compose. This experience is like “Replit for DevOps”. Here is a demo of the experience https://vimeo.com/1203095749
3 Layer 3 — Ready made extensions
Many DevOps use cases like managing kubernetes, compliance reviews, triaging an incident, AI SRE, ephemeral environments and so on are standard problem statements across organizations. DuploCloud specializes in this and hence ships with a library of extensions. For many organizations these built-in extensions fit 100% of their use cases.
The Difference — An Extensible and SLA’d foundation
Build it yourself with Claude Code and you still write skills — but everything underneath them is also yours to build, test, and maintain, with operator skill sets, no QA ecosystem, and a cost-center budget. That’s the trap. With DuploCloud, 80–90% of the functionality is already in the framework — the multiplayer runtime, RBAC, secrets, audit, determinism, retries, cost management, and analytics, all provided, SLA’d, guaranteed, and quality-tested by a company whose actual product this is. Your team writes the 10–20% that’s genuinely specific to you.
Platform Engineering didn’t fail because the idea was wrong. It failed because it asked operators to build, fund, and support a distributed system while only equipping them to write scripts — so they shipped scripts and called it a platform. AI lowered the cost of the scripts but left the distributed system unbuilt. DuploCloud supplies that distributed system as a product, so your team can start with multiplayer, team-wide DevOps agents on day one and grow into the rich Internal Developer Platform that Platform Engineering was meant to deliver all along.


