In the context of cloud operations, the last decade was ruled by DevOps and Infrastructure-as-Code. But, what is true DevOps? Is it developers running their own operations? Is it a different job role, where operators learn development skills to automate infrastructure provisioning using Infrastructure-as-Code (IaC) tools like Terraform?
Now that DevOps is widely understood in the later context, software developers are far from understanding or operating infrastructure. IaC is purely a DevOps tool. When an organization claims to have automated its infrastructure, they mean automation for the efficiency of the DevOps teams; not automation for developers. Developers are still waiting on DevOps for days, for even small infrastructure changes.
While the current DevOps model gained efficiencies, there is an increasing acknowledgment that we require a better approach to enable developer self-service. This has led to the Platform Engineering Discipline.
The high-level goals of platform engineering are:
- Developer self-service for significant parts of infrastructure updates without DevOps subject matter expertise.
- Built-in security and compliance controls.
Infrastructure-as-Code Limitations in Platform Engineering
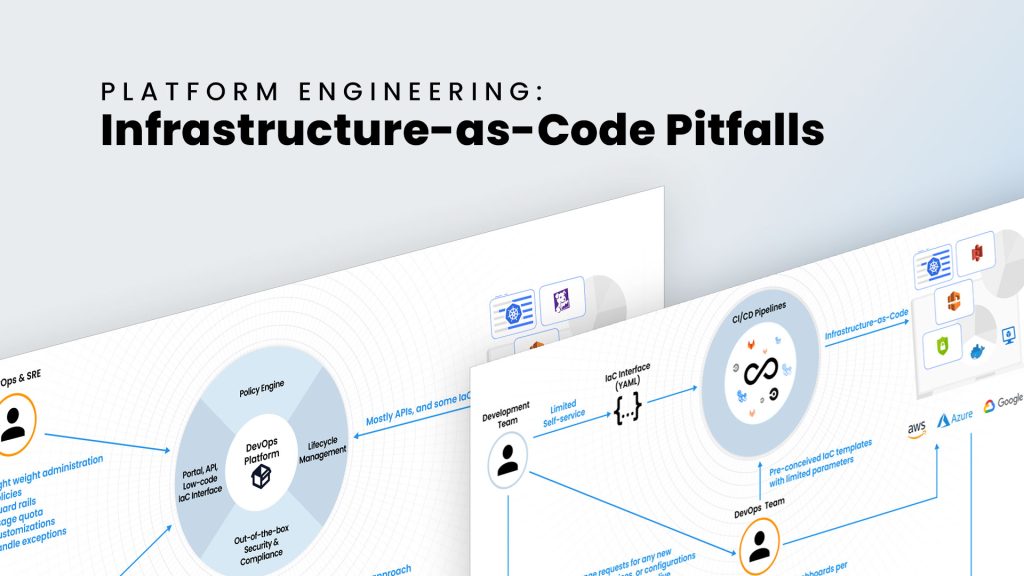
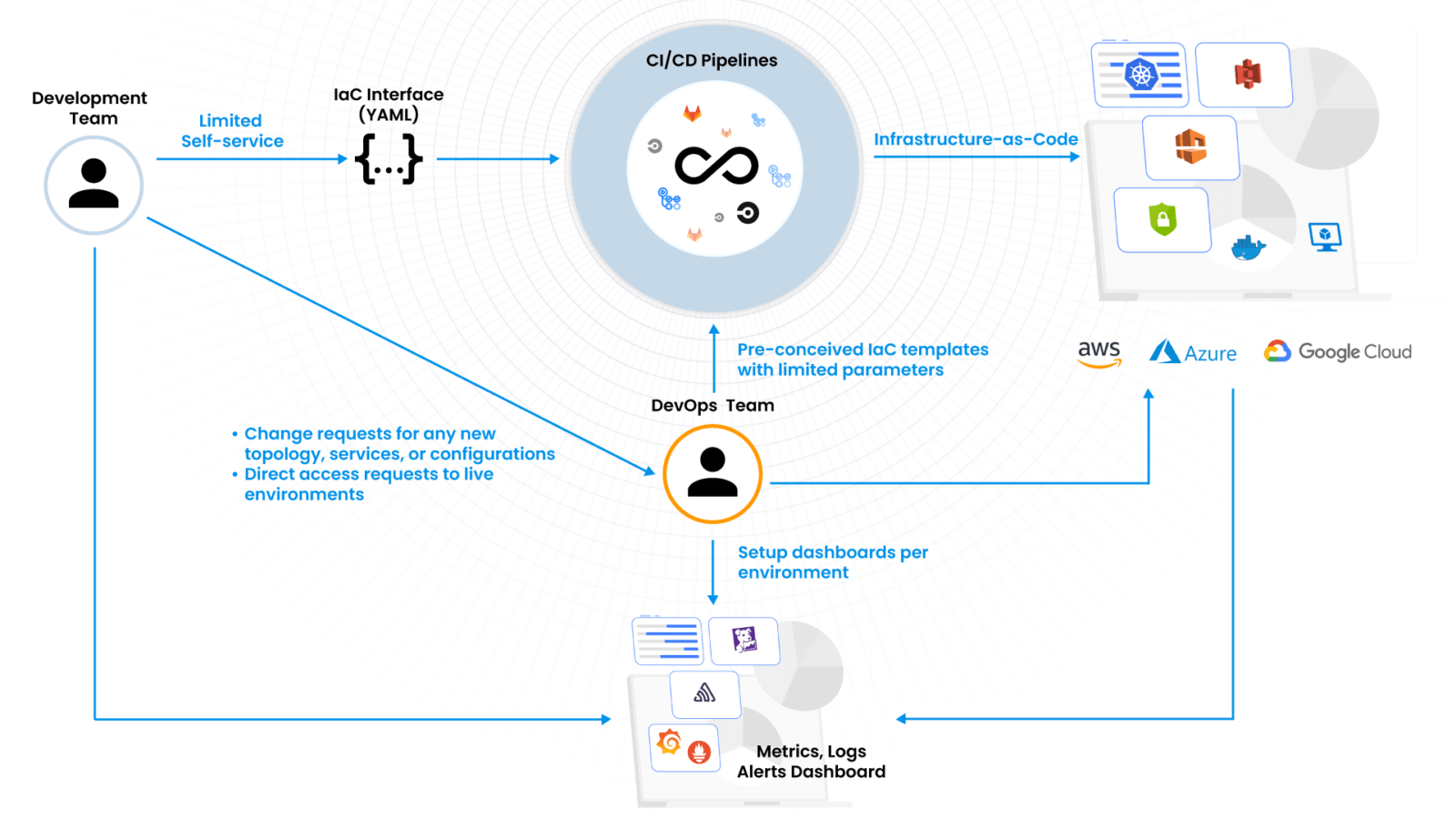
From our survey of 40+ enterprises that have made substantial investments in platform engineering, we can see that the prevalent approach is for DevOps teams to build a DevOps platform with IaC as a core underlying technology. They create templates for the organization’s use cases and publish them in a CI/CD pipeline or a self-service catalog.
Here are the top reasons why platforms that build on top of IaC are failing these platform engineering goals:
- IaC templates are rigid, opinionated, and fall short of changing developer requirements: It is true that DevOps teams can anticipate cloud infrastructure topologies to some extent and have IaC templates for those with a few customizable parameters. But in a microservices world, there are thousands of other workflows and topologies possible, based on changing application needs and security controls. A manual approach, relying solely on DevOps personnel to constantly build and update myriad combinations in static scripts simply can’t scale.
- Scripting tools can’t build lifecycle management: In cloud operations, people-triggered changes are only a subset of possible use cases. Many asynchronous operations need to be continuously performed. These range from detection of configurations, from desired state to reverting back, or complex configuration scenarios where individual components have to be set up asynchronously and brought together later. It could be as simple as a certain component going down and needing to be restored. IaC is a script that runs when triggered to completion. it has no active lifecycle to operate continuously in the background.
- Inability to build a concept of an environment: In any orchestration system, users have a concept of the environment they want to build. When they log in to the platform and navigate to their environment, they expect to update, as well as view, the state and aspects of resources in that environment, be it the provisioning status, metrics, logs, faults, audit logs, compliance posture, etc. They may want to perform debugging functions, such as restarting services, SSHinginto a VM, or accessing a resource’s cloud console (S3 Console, for example) using access control boundaries within that environment. For example, in Kubernetes you choose the namespace to be the environment and management software like Rancher on top of K8S to provide these functions. If we have to replicate this same concept across a broad infrastructure-level platform, we cannot do it with only IaC. We need something like Kubernetes, but one whose scope spans all cloud operations. Terraform is a configuration updating and management software, not an orchestration system.
Many platform teams have tried to work around these problems with point solutions by using a disparate set of jobs for certain aspects of lifecycle management, building a thin UI shim on top of cloud accounts for visualization of resources while redirecting to other systems like DataDog for logging, metrics, and alerts. But for the majority of the use cases, the DevOps team is still very much in the operations workflow. This completely defeats the concept of developer self-service as well as continuous compliance goals.
A Systems Design Approach to Platform Engineering
Two recent examples of successful cloud platforms are Amazon Web Services (AWS) in the context of Infrastructure-as-a-Service and Kubernetes for Container Orchestration. These are distributed system implementations using higher-level programming languages like Java and Go. You can’t build such complex systems using scripts and jobs.
Building a true DevOps orchestration platform requires a systems design approach. It also takes expert systems engineers and many years to build and mature, as it did for K8S and IaaS in the Public Cloud.
Figure 2 shown below illustrates a high-level design for a platform built using systems design concepts. We will discuss more on this in a subsequent blog.
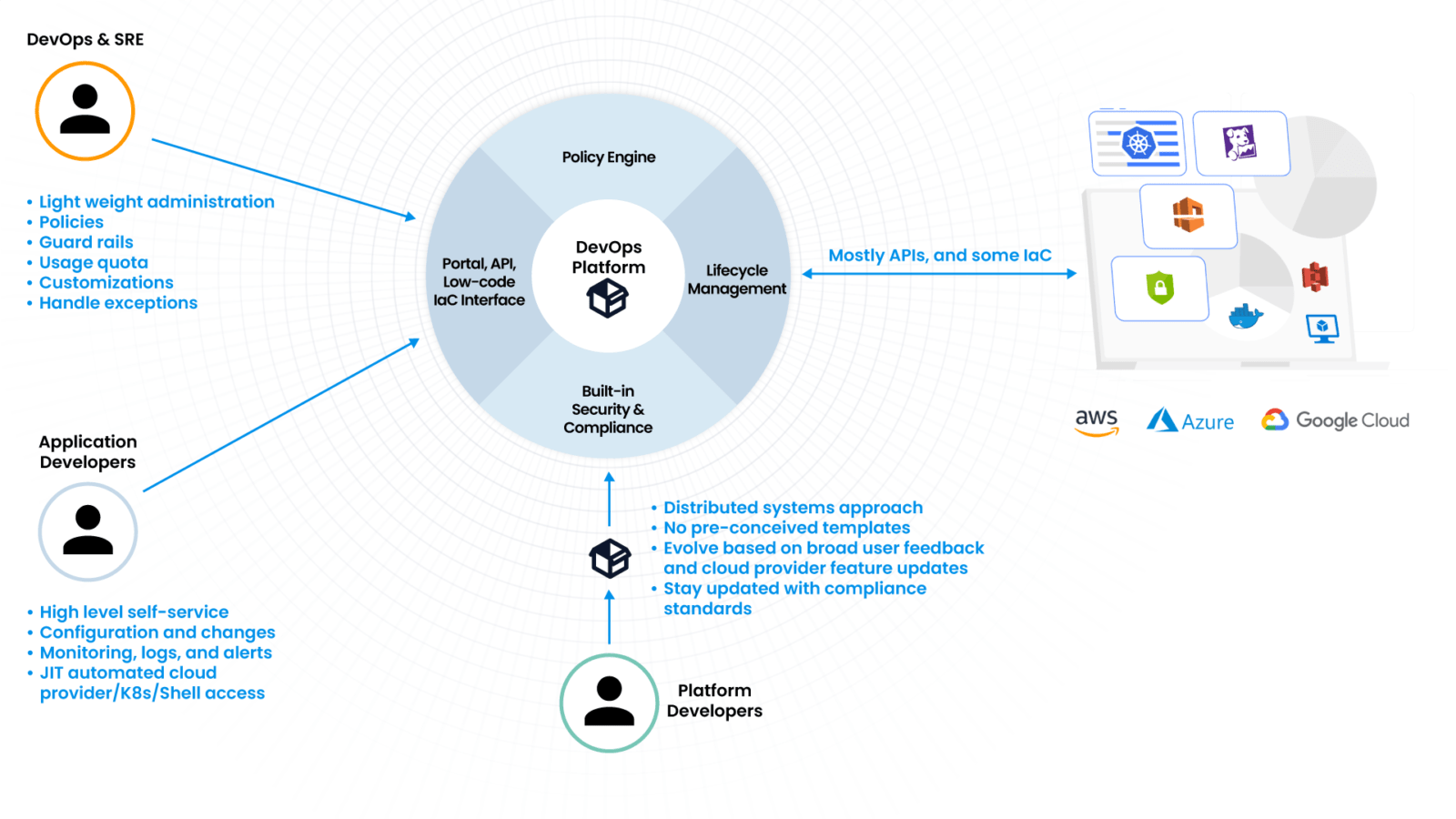
Conclusion
Since platform engineering teams need systems design expertise that is likely outside of the scope of the typical DevOps role, we need the software development function to intervene with distributed systems programmers and many years of investment. The majority of organizations trying to build in-house platforms don’t have or don’t want to make this type of investment, as it may not be their core business. Megascale tech companies like Facebook, Uber, Netflix, etc. will likely build an in-house solution, as they have the talent and scale, but for the masses, it is likely that the solution will be an off-the-shelf product from an ISV.
The industry has solved IaaS with public cloud, container orchestration with Kubernetes, and observability with platforms like Datadog. The platform engineering category is heading in the same direction as vendors like DuploCloud.


